Abstract
5D 입력 좌표(Spatial Location 및 View Direction)를 Volume Density, 뷰에 의존하는 방출된 radiance로 매핑하도록 심층 네트워크를 학습시키는 Neural Radiance Fields (NeRF)가 있다. (아래 정리 참조)
[Paper Review] NeRF : Representing Scenes as Neural Radiance Fields for View Synthesis
1. Introduction - 3D View를 생성하는 Task 수행. - 같은 물체를 다양한 시점에서 찍은 이미지가 있을 때, 이 중 일부를 학습에 사용하고 나머지로 평가하는 방식 사용. - 더 높은 주파수도 표현 가능.(=경
siyun2072.tistory.com
NeRF는 서로 다른 이미지에서 동일한 공간 위치를 쿼리할 수 있는 정적 장면에만 적용된다.
이를 해결하고자 동적 영역으로 확장하여 장면 주변을 이동하는 단일 카메라에서 경직되고 경직되지 않은 움직임 하에서 객체의 새로운 이미지를 재구성하고 렌더링할 수 있는 방법인 D-NeRF를 활용한다.
이를 위해 D-NeRF는 다음과 같은 과정이 포함된다.
1) t라는 시간 Frame 변수 사용하여 5D Input -> 6D Input으로 변화.
2) 아래의 학습 프로세스 발생.
(1) 장면을 표준 공간으로 Encoding.
(2) 특정 시간에 이 표준 표현을 변형된 장면으로 Mapping. (완전히 연결된 네트워크 사용하여 동시 학습 진행.)
* 완전 연결 신경망, Fully Connected Neural Network * = 다층 퍼셉트론
: 퍼셉트론을 기본 빌딩 블록으로 하여, 이런 패턴에 따라 2차원적으로 연결되어 구성되는 인공신경망.

3) 네트워크가 학습되면 D-NeRF는 카메라 뷰와 시간 변수를 모두 제어하여 새로운 이미지를 렌더링 할 수 있음. 그래서 객체 이동도 제어됨.
1. Introduction
정적 / 동적 객체 모두에 적용 가능한 방식을 사용한다.
But, 4D View Synthesis에 관한 기존의 방법론과는 다르다.
1) 단일 카메라를 사용하여 NeRF 가능하다.
2) 3D 재구성을 미리 계산할 필요가 없다.
3) end - to - end 방식으로 학습할 수 있다.
(end - to - end : 복잡한 파이프라인 없이 하나의 신경망으로 입력받은 것을 출력 할 수 있음.)
* 특징 *
1) Continuous 6D Function을 Input으로 사용하는 시스템을 사용. (시간 성분 t 포함.)
(x, y, z, t)로부터 density와 radiance(빛이나 열기의 발산)로 mapping하는 것을 학습하는 Nerf는 시간적 중복성을 효과적으로 활용하지 않기 때문에 만족스러운 결과를 가져오지 않는다. (시간적 중복성 :이웃한 프레임 사이의 시간 간격이 짧아 유사도가 높아지는 성질.)
=>
2) 두 개의 Module로 구성되어 학습. (컨볼루션 레이어 없이 완전히 연결된 네트워크로 학습.)
(1) 첫 번째 Module은 시간 내 장면의 각 지점과 표준 장면 구성 사이의 Spatial Mapping (x, y, z, t) → (Δx, Δy, Δz)을 학습.
(2) 두 번째 Module은 Tuple (x + Δx, y + Δy, z + Δz, θ, ɸ)을 고려하여 각 방향과 부피 밀도로 방출되는 장면 Radiance를 회귀.
2. Related Work
1) Neural Implicit Representation for 3D geometry.
2D 영역에서 딥러닝의 성공은 3D 영역에 대한 관심을 증가시켰다.
하지만, 딥러닝에 가장 적합한 3D 데이터 표현은 Nonrigid Geometry(비강체 기하학)에 대해 열린 결말로 남아 있다.
최근, 신경망을 통해, 암시적으로 3D Data를 표현하는 방법들이 대두되고 있다. 주된 아이디어는 Neural Network의 Output을 3D Point의 정보로 묘사하는 것이다. 하지만, 이러한 방법들은 Nerf가 대두되기 전 상당히 제한적이었다.
Nerf는 5D Radiance Fields를 활용하여, Rigid Scene를 고해상도와 현실적인 장면처럼 표현하는 것이 가능합니다.
하지만, 저자가 논문에서 언급했던 모든 방법들은 Rigid Scene에서 좋은 결과를 얻는 것이 가능했지만, Dynamic하고 변형가능한 장면을 처리하는 방법은 없다. 본 논문에서는 3D Ground-Truth와 Multi-View Camera Setting없이 D-NeRF가 시간에 따른 Non-Rigid와 Time-Varying Scene에 대한 것들을 암묵적으로 표현가능하다는 것을 보여준다.
2) Novel view synthesis.
- D-NeRF는 이전의 연구들과는 달리 (1) 3D 재구성이 필요하지 않고, (2) end-to-end로 학습하는 것이 가능하며, (3) 시간에 따른 Single View가 요구됩니다. 또한, 시간에 따라 변하는 (4) 3D Volume Density와 Emitted Raidance를 본질적으로 학습한다.
3. Problem Formulation
Monocular Camera(환경에서 3D Point를 추정할 수 있음.)로부터 얻은 이미지들을 고려하여, 임의의 시간에 장면을 암시적으로 인코딩하고 새로운 뷰를 합성할 수 있는 딥러닝 모델을 설계하고자 한다.

Mapping M : (x, d, t) → (c, σ)를 추정하고자 한다. (시간 순간 : t)
직관적인 해결책은 6D 공간(x, d, t)에서 4D 공간(c, σ)로 Mapping하는 Transformation M을 학습하는 것이다.
하지만, 논문의 Result Section에서 볼 수 있듯 Mapping M을 (1) Ψ_x = (표준 구성의 장면), (2) Ψ_t = (순간 t의 장면과 표준 구성의 장면 사이의 Mapping) = (순간 t에서 점 x와 뷰 방향 d가 주어지면 (x,t) -> Δx으로 변환)으로 분할하여 도출하는 것이 더 나은 결과를 얻을 수 있다.
일반성의 Loss 없이 즉, 시간 인스턴스 간에 독립적이지 않고 공통의 표준 공간 앵커를 통해 상호 연결하고자 (1)과 같이 선택하였다.
(1) 표준 장면 Ψ_t : (x, 0) → 0으로 t = 0을 선택하였다.
(2) 표준 구성 Ψ_x : (x + Δx, d) → (c, σ)로 변경된다.
4. Method
NeRF는 Rigid Scene(Point의 모션은 서로 독립X)의 여러 장면들을 회상하는 것을 요구되지만, D-NeRF는 Single View per Time로 학습된 Continuous Non-Rigid Scenes(Point의 모션은 서로 독립O)의 Volumetric Density Representation을 학습하는 것이 가능하다.

두 가지 신경망 모듈은 이전 섹션 Ψ_t, Ψ_x에서 설명한 매핑을 매개 변수화한다.
첫 번째 모듈은 Canonical Network(4.1 참조)를 사용하여 MLP(Multi Layer Perceptron) Ψ_x(x, d) → (c, θ)가 표준 구성의 장면을 인코딩하도록 학습되어 주어진 3D 포인트 x와 뷰 방향 d가 방출된 색상 c와 볼륨 밀도 σ를 반환한다.
두 번째 모듈은 Deformation Network(4.1 참조)라고 하며 시간 t의 장면과 표준 구성의 장면 사이의 변환을 정의하는 변형 필드를 예측하는 또 다른 MLP Ψ_t(x, t) → Δx로 구성된다.
4.1 Model Architecture
1) Canonical Network (Ψ_x)
표준 구성을 사용하여 모든 이미지에서 모든 해당 점의 정보를 결합하는 장면의 표현을 찾고 있다.
이를 통해 특정 관점에서 놓친 정보를 표준 구성에서 가져올 수 있다.
Canonical Configuration 내 Scene의 색상과 밀도를 인코딩하기 위한 방법으로 학습된다.
구체적으로 점의 3D 좌표 x가 주어지면, 먼저 그것을 256차원 Feature Vector 로 인코딩한다. Feature Vector는 카메라 뷰 방향 d와 연결되고 Fully Connected Layer를 통해 표준 공간에서 해당 점에 대해 방출된 색상 c와 부피 밀도 σ를 산출한다.
2) Deformation Network(Ψ_t)
특정 시간 순간의 장면과 표준 공간의 장면 사이의 변형 필드를 추정하도록 최적화되어 있다.
시간 t에서 3D 점 x가 주어지면 Ψ_t는 주어진 점을 표준 공간의 위치로 변환하는 변위 Δx를 x + Δx로 출력하도록 학습된다.
모든 실험에는 일반성의 Loss없이 표준 장면을 시간 t=0의 장면으로 설정한다. :

4.2 Volume Rendering
6D Neural Radiance Field에서 Non-Rigid Deformations(변형)을 설명하기 위해 기존 NeRF Volume Rendering 방식을 조정한다.

- x(h) = o + hd : 투영 중심 o에서 픽셀 p로 방출되는 카메라 ray를 따른 점들의 선.
- h_n : 근거리 경계.
- h_f : 원거리 경계.
- p(h,t) : Deformation Network Ψ_t를 사용하여 표준 공간으로 변환된 카메라 Ray x(h)의 점.
- T(h,t) : h_n에서 h_f로 방출된 ray가 다른 입자에 부딪히지 않을 누적 확률.
- 밀도 σ와 색상 c는 Canonical Netowkr Ψ_x에 의해 예측된다.
(2), (5) 식에서 Volume Rendering 적분은 수치 적분(임의의 구간에 피적분함수를 포함한 적당한 급수함으로 근사하여 수치적으로 구하는 것)을 통해 근사화 될 수 있다. ({h_n}_(n=1)^N ∈ [h_n, h_f])

- δ_n = h_(n+1) - h_n : 두 직교 점 사이의 거리
4.3 Learning the Model
1) 장면의 T RGB 이미지 {I_t}_(t=1)^T와 해당 카메라 포즈 행렬 {T_t}_(t=1)^T에 대한 평균 제곱 오차를 최소화하여 표준 Ψ_x 및 변형 Ψ_t 네트워크의 매개 변수를 동시에 학습한다.
2) 각 학습 배치에서 먼저 일부 카메라 위치 T_t에서 해당 RGB 이미지 t의 일부 픽셀 i로 투사되는 ray에 해당하는 임의 픽셀 집합 {p_(t,i)}_(i=1)^N_s를 샘플링한다.
3) 픽셀 색상 근사화 식을 사용하여 선택된 픽셀의 색상을 추정한다.
4) 학습 Loss는 렌더링된 픽셀과 실제 픽셀 사이의 평균 제곱 오차를 줄이기 위해 학습한다.

- ^C : 픽셀의 Ground-Truth 색상.
5. Implementation Details (논문 번역)
Canonical Network Ψ_x와 Deformation Network Ψ_t 모두 ReLU 활성화 함수가 있는 단순한 8-Layers MLP로 구성된다.
Canonical Network의 경우 c와 σ에 최종 Sigmoid 비선형성이 적용되지만, Deformation Network의 Δx에는 비선형성이 적용되지 않는다.
모든 실험에 대해 위의 표준 구성 식(Ψ_t)을 시행하여 t = 0에서 장면 상태로 설정한다.
네트워크 수렴을 개선하기 위해 입력 이미지를 타임 스탬프(낮은 이미지에서 높은 이미지로)에 따라 정렬한 다음 더 높은 타임 스탬프를 가진 이미지를 점진적으로 추가하는 커리큘럼 학습 전략을 적용한다.
이 모델은 N_s = 4096 ray의 배치 크기를 가진 800k 반복 동안 400×400 이미지로 학습되며, 각각은 ray를 따라 64번 샘플링된다.
옵티마이저의 경우 학습 속도가 5e - 4, β_1 = 0.9, β_2 = 0.999이고 5e - 5로 지수 감쇠하는 Adam을 사용한다.
모델은 이틀 동안 단일 Nvidia® GTX 1080으로 학습된다.
6. Experiments
6.1에서는 Canonical 및 Deformation Network를 테스트한다.
6.2에서는 D-NeRF를 NeRF, T-NeRF(표준 매핑을 사용하지 않는 변형)와 비교한다.
6.3에서는 여러 복잡한 동적 장면에서 임의의 시간에 새로운 뷰를 합성할 수 있는 D-NeRF 능력을 보여준다.
6.1 Dissecting the Model
실험1)
- 1번쨰 열의 Rendering된 RGB이미지는 픽셀 색상 근사화 식을 통하여 임의의 카메라 위치에서 캐스팅된 Ray에 대한 Canonical Network를 평가한 결과이다.
- 2번째, 3번째 행은 t=0.5 및 t=1에 대한 표준 공간에 해당하는 변환 벡터를 적용한 결과를 보여준다.
- 4번째 열에서 시간에 따른 색상 일치성을 평가하면, 변위 필드가 올바르게 추정되었음을 확인할 수 있다.

실험 2) D-NeRF모델이 동일한 점의 외관 변화를 인코딩할 수 있는지를 알기 위해 특정 시간 순간에 표준 구성과 장면 사이의 대응하는 점의 쌍을 표시하여 실험을 진행했다.
그 결과, 빨간색 공의 그림자에 있는 점은 표준 공간의 서로 다른 영역에서 t=0.5 및 t=1 맵이다.
=> 따라서, D-NeRF 모델은 표준 구성을 왜곡하여 음영 효과를 합성할 수 있다.

6.2 Quantitative Comparison
- D-NeRF를 NeRF, T-NeRF(표준 매핑을 사용하지 않는 변형)와 질적 및 정량적으로 비교했다.

시각적인 검사를 위해 새로운 뷰 아래에 추정된 이미지의 샘플을 보여준다.
NeRF는 Rigid case를 위해 설계된 것처럼 Dynamic Scene을 모델링할 수 없으며 항상 모든 변형의 블러 평균 표현으로 수렴한다.
T-NeRF은 Dynamic Scene을 잘 포착할 수 있지만, 고주파 세부 정보를 검색할 수 없다.
(ex. 왼쪽 위 이미지에서는 숄더 패드 스파이크를 인코딩하지 못하고 오른쪽 위 장면에서는 돌과 균열을 모델링할 수 없다.)
D-NeRF는 새로운 뷰에서 원래 이미지의 높은 세부 정보를 유지한다.
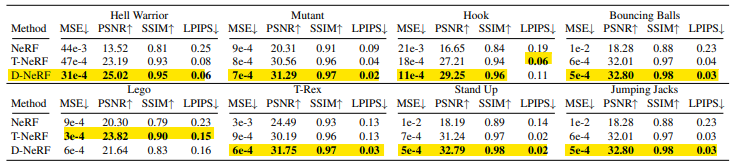
- MSE : Mean Squared Error
- PSNR : Peak Signal-toNoise Ratio
- SSIM : Structural Similarity
- LPIPS : Learned Perceptual Image Patch Similarity
6.3 Additional Results

7. Conclusion
D-NeRF는 움직이는 카메라로 획득한 희소한 이미지 세트에서만 종단 간 학습이 가능하며, 사전 계산된 3D priors나 다른 관점에서 동일한 장면 구성을 관찰할 필요가 없다. 주요 아이디어는 두 개의 모듈로 시간 변동 변형 (1) 표준 구성을 학습하는 것과 2) 표준 공간에 대해 매 순간 장면의 변위 필드를 학습하는 것)을 나타내는 것이다.
참조 :
D-NeRF: Neural Radiance Fields for Dynamic Scenes
Neural rendering techniques combining machine learning with geometric reasoning have arisen as one of the most promising approaches for synthesizing novel views of a scene from a sparse set of images. Among these, stands out the Neural radiance fields (NeR
arxiv.org
